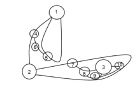
Självlärande Rock - papper - sax Robot från Lego Mindstorms NXT! (2 / 5 steg)
Steg 2: Hur roboten lär sig om det inte fuska?! (Del 1)

Roboten skapar en virtuell databas (för er dator nördar, den använder en 3 dimensionell matris för att göra detta!). Tror denna databas som en Rubiks kub. Roboten har att hålla reda på tre saker: 1) flyttar spelaren in (rock, papper eller sax); 2) flytta roboten gjorde (igen rock, papper eller sax); och 3) resultatet av denna runda (gjorde robot vinna, förlora eller slips med spelaren?). I den här databasen kommer roboten faktor i en sannolikhet för framgång för detta drag. Det här värdet lagras i matrisen, eller (med Rubiks kub analogi) i en av 27 kuber.
Till exempel, om spelaren har valt ROCK, men roboten välja sax, roboten förlorat, så det kommer in en framgång på 0% för att spela sax när spelaren väljer rock i framtiden.
För att uppmuntra roboten att lära sig, belöna jag roboten med hjälp av virtuella poäng ett! En analogi är som en liten unge. Om jag gick upp till grabben och sa, "Hej, jag ska ge dig $20 om du kan lära dig att flyga själv!", kommer att ungen tänka, "Wow! $20! Det är en bra belöning! Låt mig försöka! ". Ungen kommer först krypa, sedan promenad, sedan kör, och sedan hoppa i ett försök att fly och få $20 belöningen. Ungen lär dock så småningom att han/hon inte kan flyga utan ett flygplan, och kan inte lyckas. Men längs vägen, grabben hade lärt sig hur krypa, gå, springa och hoppa!
Jag tillämpas dessa principer till roboten! I stället för kontanter ger (skulle jag allvarligt slösa min tid försöka ge min robot $20?!), jag roboten en virtuell punkt (+ 1) om roboten slår spelaren. MEN, jag kommer att ta bort 10.000 virtuella poäng från roboten (ja jag är snål) om roboten antingen förlorar eller band med spelaren. Då roboten vill maximera antalet poäng det vinster, används framgång sannolikheterna i sin databas för att uppnå detta mål.
Hur att spela Rock, papper, sax, ödla, Spock

Rock papper sax ödla Spock skrivbord leksak

Arduino Rock-papper-sax

Solar Powered Lego Mindstorms NXT Robot

Hur man bygger en Lego Mindstorms NXT hexapod robot?

Lego Mindstorms NXT robot Hand prototyp

Hur man bygger en Lego Mindstorms NXT OCTOPOD robot?
Java-programmering 1 | Rock, papper och sax

ROCK, papper, SISSORS, ödla, SPOCK, kortspel
Rock, Paper, sax - brädspelet.

Wii NunChuck kontrollerade Mindstorms NXT fotboll Robot

Sten papper sax
Solar Powered Mindstorms NXT Robot

Självlärande IR-fjärr kontrollerade switch

S3NTRY: en LEGO Mindstorms robot sentry tornets

Java Rock, Paper, Scissors

Rock, Paper, Scissors Math spel att lära vinklar

Penna & papper Catan - för nödsituationer