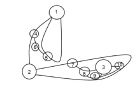
Självlärande Rock - papper - sax Robot från Lego Mindstorms NXT! (3 / 5 steg)
Steg 3: Hur roboten lär sig om det inte fuska?! (Del 2)

Den viktigaste variabeln kallas EPSILON. Denna variabel är också känd som den lärande skattesatsen. Epsilon startar ut löjligt höga, som orsakar roboten att göra slumpmässiga flyttar i början av spelet. När roboten spelar mer (och därför lär de bästa drag mot spelaren), minskar Epsilon. Eftersom Epsilon blir mindre, över tiden, börjar roboten långsamt att använda framgång sannolikheterna i sin databas mot spelaren.
Tre andra variablerna: ALPHA, GAMMA och KAPPA.
Alpha håller reda på hur mycket varje drag påverkar robotens lärande. Det låter förvirrande! Faktiskt, Alpha avsiktligt anges till så nära noll som möjligt. Om en spelare ligger (* suck *) till roboten (säga om spelaren har valt rock, och roboten valde papper, men spelaren hävdar att roboten förlorat), ett lågt värde för Alpha kommer att orsaka roboten att ignorera lögn! Dock om Alpha är för låg, lär då roboten inte så snabbt.
Gamma är en belöning. Gamma ligger högt (0.80) eftersom som Gamma närmar sig 1, roboten är mer benägna att börja använda framgång sannolikheter förr.
Kappa är en grundlighet värde som hjälper roboten förfina dess sannolikheter.
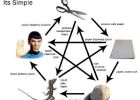
Hur att spela Rock, papper, sax, ödla, Spock

Rock papper sax ödla Spock skrivbord leksak

Arduino Rock-papper-sax

Solar Powered Lego Mindstorms NXT Robot

Hur man bygger en Lego Mindstorms NXT hexapod robot?

Lego Mindstorms NXT robot Hand prototyp

Hur man bygger en Lego Mindstorms NXT OCTOPOD robot?
Java-programmering 1 | Rock, papper och sax

ROCK, papper, SISSORS, ödla, SPOCK, kortspel
Rock, Paper, sax - brädspelet.

Wii NunChuck kontrollerade Mindstorms NXT fotboll Robot

Sten papper sax
Solar Powered Mindstorms NXT Robot

Självlärande IR-fjärr kontrollerade switch

S3NTRY: en LEGO Mindstorms robot sentry tornets

Java Rock, Paper, Scissors

Rock, Paper, Scissors Math spel att lära vinklar

Penna & papper Catan - för nödsituationer