3D utskrift San Francisco kloakerna (2 / 12 steg)
Steg 2: Ren datamängder

Detta var en iterativ process och så småningom fick jag det sorterade men inte utan en massa timmar och huvudvärk.
Den viktigaste frågan med data är att:
(1) det var inte helt rena, vilket innebär att uppgifterna som rör inte matcha upp med alla noder. Det fanns några ID-strängar som var dubbleras, saknas och mycket mer. Det var mestadels bra, men det behövs algoritmisk vård.
(2) när jag monterade noderna, fanns det en massa små, isolerade sub nätverk i stället för en gigantisk nätverk av data. Jag började med cirka 30.000 datapunkter och "primära" nätverket var cirka 28.000 poäng. Jag slutade med alla sorters mini-nätverk av rör data: allt från 2-100 i storlek. 3d-tryck-objekt, dessa måste vara en enda, sammanhängande objekt, annars 3D tryck kommer att falla sönder.
Min parser kod gör sitt bästa att rensa data och kasta det jag inte behöver.
Jag skrev koden i Java, vilken inte är den mest effektiva motorn: det är både långsamt och kod-tung, men det är ett språk som jag känner väl är finns det många bra JSON bibliotek för det som Eson bibliotek.
Json-libs i OpenFrameworks — öppen C++ toolkit — skulle ha varit snabb, men kräver en hel del extra sammanställningen. Även när de kör, hamna de inte ger mig customizability som jag har i Javas data fältet exporten.
Python erbjuder bra tolkning verktyg, men inte en anständig nog UI. JavaScript är förmodligen den bästa lösningen, men jag vet inte miljön tillräckligt bra (ännu).

Vattenverk: 3D utskrifter av San Francisco vattensystemet med karta

Grunderna i 3D utskrift på en typ en serie 1 Beta: gjort på Techshop: San Francisco
Hur till göra en lasern skär karta över San Francisco

Sociala kretsmönster i San Francisco

San Francisco: Förflutna, nutid, framtid

San Francisco arkipelagen

San Francisco arkitektoniska silver

3D modellering San Francisco cisterner

2012 San Francisco Flugtag flyger flygplansmodell

Hur du registrerar ditt barn i kommunal skola i San Francisco

Hur man rida MUNI bussen (San Francisco)
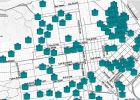
Mappning av San Francisco cisterner

Hur du använder konferens rum projektorn på TechShop San Francisco

Hur kan man vara en bra hundägare i San Francisco

Träd vindruta, San Francisco

Hur man får ett träd på din block i San Francisco

Hur att vara värd för en Park Clean-Up i San Francisco

Hur man handlar för dagligvaror (San Francisco)
