Enkel, kraftfull Web skrapa på 5 minuter (2 / 4 steg)
Steg 2: Din första skrapa: greppa användarnamn från en Reddit tråd


https://www.Reddit.com/r/Arduino/comments/3rixq5/i...
Det första steget i att bygga en skrapa kommer alltid att vara
identifiera vad våra nyckelinformation är märkt. I det här fallet vill vi att alla användarnamn i kommentarerna i en reddit tråd. Så vi kommer att använda google Chromes inspektera element verktyg för att ta reda på vad username är märkt som. (bild 1)
Detta bör ta upp följande terminalen med användarnamnet belyst: (2)
Vi ser att alla användarnamn i en reddit tråd är relaterade till länkar med klassen "författare". Nu här är den svåra biten: vi behöver något sätt att sortera igenom alla olika webbsideelement för att nå fram till taggen med klassen "författare". Som ni kan se det inte är en lätt resa eftersom dessa länkar ligger i den:
< div class = "commentarea" >
som sedan sjunker ner i
< div id = "siteTable_t3_3rixq5" class = "sitetable nestedlisting" >
som droppar in ännu mer HTML-element. Att minimera den
mängden javascript vi har att skriva, ska vi lägga ut faktiska tolkning av vår webbsida till Yahoos YQL språk. Detta kommer att passera genom alla de olika HTML-element och returnera oss dessa dyrbara Taggar som vi önskar. Oroa dig inte om du är förvirrad just nu. Nästa steg kommer att göra det mer tydliga.

Super enkel kraftfull Flyback förare

Power led blottare-enkel, kraftfull och effektiv!

Göra en enkel, billig kajak stå under 15 minuter
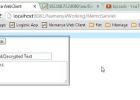
Hur man konsumerar en enkel Java Web tjänst från C++(Legacy) & Java-program

Hur man gör en enkel, kraftfull och bärbar gummiband pistol

Enkel, kraftfull knex rod shooter

Gör en enkel pull-back launcher i 5 minuter eller mindre!

1 minut mikrovågsugn lax paj i en kopp

Enkel mobil laddare

Super enkelt tredje handverktyg inom 30 minuter

Web kontrollerade Arduino LED

Ultimate Raspberry Pi Home Server

Paleo banan glass tryffel

Pizza knappen

$3 akut Solar Radio

Spectrographic Auroral indikator - en Northern Lights varning enhet

Hemgjord bugg bita Balm

Syra etch
